Predicting Gaze in Python with the Eye Tracking for Everyone Neural Network
Nov 13, 2017 22:21 · 722 words · 4 minutes read
View the ipython notebook with the code here
My next goal for Presence was to try to get eye gaze prediction working using the Eye Tracking for Everyone model. I wanted to get it working in Python so that it would be platform agnostic; the idea would be to eventually get this working on any computer with a webcam and decent GPU. The ultimate deployment would be on the NVidia Jetson TX2, a single-board computer with a powerful GPU and support for six camera inputs.
For the neural network framework I stuck with caffe since that’s what the model is published in. I struggled for days but finally setup Ubuntu with caffe and cuda on my macbook pro, which has a basic NVIDIA GeForce GT 650M graphics card.
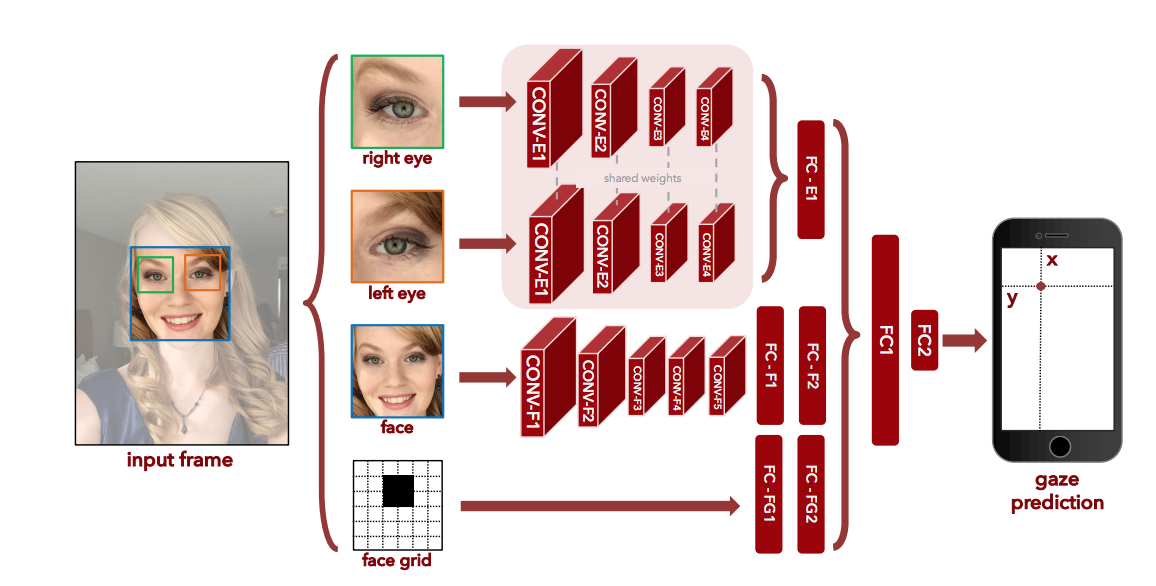
The convolution neural network architecture. See the research paper for details.
I used OpenCV to extract the face and eye features, and calculated the 25x25 face grid with code from faceGridFromRect.m that I converted to python. I then loaded their model, and fed the inputs through the network.
For all pictures tested I used the selfie camera in portrait mode on an IPhone 8. Since the network outputs the distance from the camera in cm, I could convert this to pixel space on the screen based on the resolution of the pictures and the physical dimensions of the phone.
View the ipython notebook with all of the code here
Results
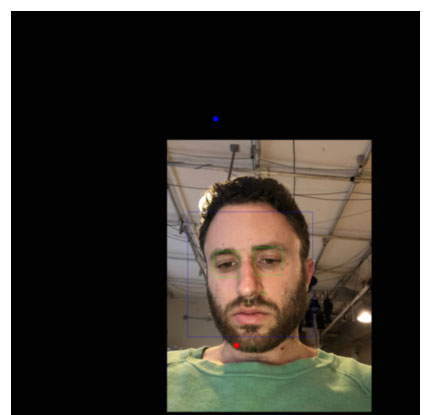
For each picture the blue dot is where the camera was, and the red dot is where the gaze was predicted to be. The blue and green square are where the faces and eyes are detected with open cv correspondingly.
Multiple people and gazes I told him to look at the camera when taking this.


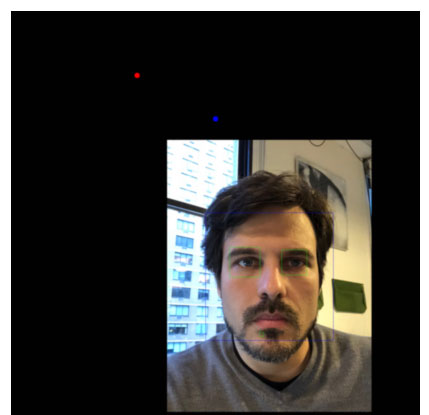
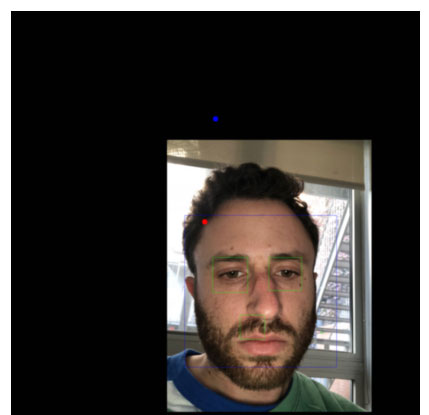
A bad prediction
Performance
I tried testing the network on my Macbook Pro’s GPU which has 1 gb of ram, but got the Cuda error that there was not enough memory. On the CPU, testing the network takes about 2.2s.
I then setup Ubuntu, caffe, and cuda on my home gaming pc which is an Alienware X51 and has a GTX 970 with 4 gb of ram. On this setup, it was able to run on the GPU and that step around 100 ms. The bottleneck ended up being the opencv detection part, which takes about 0.5s.
The goal is to do real-time gaze detection. A total runtime of around 0.6 seconds to detect gaze is acceptable for the installation with physical motors, as it is enough time for the motors to change to reflect the new gaze.
To lower the runtime, I plan on optimizing the OpenCV face and eye detection to perform faster. I would also want to experiment with using a neural network based face detector such as OpenFace.
Also, in the research paper they say they were able to compress the model and run it in real-time on an IPhone. This model is not available on the github page. I’m going to ask the researchers for this compressed version so that it could run quickly on less demanding gpus such as my Macbook Pro’s.
Conclusion & Next Work
I’m thrilled with this experiment as for the most part the results came out pretty accurate, and I’m more confident now this can be used to predict gaze for the installation. The neural network outputs the x and y distance from the camera in centimeters, which is easily usable for a physical installation where we know how far everything is from the camera.
I need to test how well this would work when gazing at a bigger space than just the area round the screen. This accuracy will determine how large the final installation will be, as if there is a high error rate when gazing far away from the camera, then the experience will suffer at those distances, so it will need to be smaller.
To Dos:
- Connect to a webcam and detect eyes and gazes in realtime. Display where the gaze is predicted to be in the physical space of a large monitor.
- With OpenCV, determine which is the left and right eye, and feed the proper eye to the proper side of the network.
- Try to obtain the compressed model from the researchers, and see how it to run on my Macbook Pro’s GPU